Table of Contents
- What is Data Collection?
- Types of Data
- Methods of Data Collection
- Qualitative vs Quantitative Data
- Importance of Accurate Data Collection
- Technological Advancements in Data Collection
- Understanding Data Processing
- Steps in Data Processing
- Challenges in Data Processing
- Best Practices for Processing Results
- Ethical Considerations in Data Collection and Processing
- Regulatory Compliance and Data Privacy
- Case Studies in Successful Data Collection and Processing
- Future Trends in Data Collection and Processing
- FAQs
- Conclusion
What is Data Collection?
Data collection is the process of gathering information from various sources to be used for analysis and decision-making. It is a fundamental step in the research process and serves as the foundation for generating insights. The primary objective of data collection is to obtain accurate and reliable information that can lead to meaningful conclusions. This process involves identifying the data sources, selecting appropriate data collection methods, and implementing tools and techniques to gather the required information efficiently.
The scope of data collection can vary significantly depending on the nature of the research and the objectives. It can range from simple surveys to complex experiments, each requiring a tailored approach to ensure the validity and reliability of the data collected. The choice of data collection methods is influenced by factors such as the type of data needed, the resources available, and the time constraints.
In the digital age, data collection has become more sophisticated and accessible, enabling researchers to gather vast amounts of data from diverse sources. With the rise of the internet, social media, and mobile technology, data collection has transcended traditional boundaries, allowing for real-time data acquisition and analysis. This transformation has opened new avenues for research and innovation, making data collection a critical component of modern-day research and decision-making.
Types of Data
Data can be classified into various types based on its characteristics and the context in which it is used. Understanding the different types of data is essential for selecting the appropriate data collection and processing methods. Generally, data is categorized into the following types:
- Qualitative Data: This type of data is descriptive and non-numerical, providing insights into the characteristics, qualities, or attributes of a subject. Qualitative data is often collected through interviews, focus groups, and open-ended surveys, allowing for a deeper understanding of the subject matter.
- Quantitative Data: Quantitative data is numerical and can be measured or counted. It provides objective information that can be analyzed statistically. Common methods of collecting quantitative data include structured surveys, experiments, and observations that yield numerical results.
- Primary Data: This is original data collected firsthand by the researcher for a specific purpose or study. Primary data is often gathered through direct interaction with participants or subjects, ensuring its relevance and accuracy.
- Secondary Data: Secondary data is information that has been collected by someone else for a different purpose but is being used by the researcher for their study. This type of data can be obtained from sources such as published articles, books, reports, and databases.
- Structured Data: Structured data is organized and formatted in a way that is easily searchable and analyzable. It typically resides in databases and spreadsheets, allowing for efficient data processing and analysis.
- Unstructured Data: Unstructured data lacks a predefined format or organization, making it more challenging to analyze. It includes data such as text documents, images, videos, and social media posts.
The choice between different types of data depends on the research questions, objectives, and the type of analysis required. A clear understanding of the data types is crucial for designing an effective data collection strategy and ensuring the integrity of the results.
Methods of Data Collection
Data collection methods are techniques and tools used to gather information for analysis. The selection of appropriate methods is critical to the success of the data collection process, as it influences the accuracy, reliability, and validity of the data obtained. There are several methods of data collection, each suited to different research objectives and contexts:
- Surveys and Questionnaires: Surveys and questionnaires are common data collection tools used to gather information from a large number of respondents. They consist of a series of questions designed to elicit specific responses, which can be analyzed quantitatively or qualitatively.
- Interviews: Interviews involve direct interaction between the researcher and the participant, allowing for in-depth exploration of a subject. They can be structured, semi-structured, or unstructured, depending on the level of flexibility required.
- Observations: Observational methods involve systematically watching and recording behaviors or events as they occur. This method is particularly useful for studying phenomena in their natural settings.
- Experiments: Experiments are controlled studies designed to test specific hypotheses by manipulating variables and observing the outcomes. This method provides a high level of control and precision in data collection.
- Focus Groups: Focus groups involve guided discussions with a small group of participants to explore their perceptions, opinions, and attitudes on a particular topic. This method is valuable for generating qualitative insights.
- Secondary Data Analysis: This method involves analyzing existing data collected by other researchers or organizations. It allows for the exploration of new research questions without the need for primary data collection.
Each data collection method has its advantages and limitations, and the choice of method depends on factors such as the research objectives, available resources, and the nature of the data required. A well-designed data collection strategy ensures the reliability and validity of the information gathered, leading to meaningful and actionable insights.
Qualitative vs Quantitative Data
Understanding the distinction between qualitative and quantitative data is essential for selecting the appropriate data collection and analysis methods. These two types of data serve different purposes and provide unique insights into the subject matter:
Qualitative Data: Qualitative data is descriptive and focuses on understanding the qualities, characteristics, or attributes of a subject. It provides a deeper understanding of the underlying motivations, opinions, and behaviors of individuals or groups. Qualitative data is often collected through methods such as interviews, focus groups, and open-ended surveys. The analysis of qualitative data involves identifying patterns, themes, and insights that can inform decision-making.
Quantitative Data: Quantitative data is numerical and can be measured or counted. It provides objective information that can be statistically analyzed to identify trends, patterns, and relationships. Quantitative data is often collected through structured surveys, experiments, and observations that yield numerical results. The analysis of quantitative data involves using statistical techniques to draw conclusions and make predictions.
Both qualitative and quantitative data have their strengths and limitations. Qualitative data provides rich, detailed insights, but it may be subjective and harder to generalize. Quantitative data offers the advantage of statistical analysis and generalizability, but it may lack the depth of understanding provided by qualitative data. In many cases, a mixed-methods approach that combines both qualitative and quantitative data collection and analysis is used to leverage the strengths of each type and provide a comprehensive understanding of the research problem.
Importance of Accurate Data Collection
Accurate data collection is crucial for ensuring the reliability and validity of research findings and for making informed decisions. The quality of the data collected directly impacts the insights generated and the outcomes of the research process. Here are some reasons why accurate data collection is essential:
- Ensures Validity: Accurate data collection ensures that the data accurately represents the phenomena being studied, leading to valid and credible research findings.
- Enhances Reliability: Reliable data collection methods produce consistent and repeatable results, allowing for the verification and replication of research findings.
- Provides Actionable Insights: High-quality data collection leads to actionable insights that can inform decision-making, policy development, and strategic planning.
- Reduces Bias: Accurate data collection minimizes biases and errors in the research process, leading to more objective and unbiased findings.
- Facilitates Data Analysis: Accurate and well-organized data makes the analysis process more efficient and effective, enabling researchers to draw meaningful conclusions and make data-driven decisions.
The importance of accurate data collection cannot be overstated, as it forms the foundation for all subsequent stages of the research process. Implementing best practices and methodologies in data collection helps ensure the integrity and reliability of the data, ultimately leading to more robust and impactful research outcomes.
Technological Advancements in Data Collection
The rapid advancement of technology has transformed the landscape of data collection, making it more efficient, accurate, and accessible. Technological innovations have enabled researchers to collect data from diverse sources in real-time, expanding the possibilities for research and analysis. Some key technological advancements in data collection include:
- Online Surveys: The advent of online survey tools has revolutionized data collection by allowing researchers to reach a wide audience quickly and cost-effectively. These tools provide features such as automated data entry, real-time analysis, and easy customization.
- Mobile Data Collection: Mobile technology has enabled data collection through smartphones and tablets, providing flexibility and convenience. Mobile data collection apps allow researchers to gather data in the field, even in remote or challenging environments.
- Social Media Analytics: Social media platforms generate vast amounts of data that can be analyzed to gain insights into consumer behavior, trends, and public sentiment. Social media analytics tools facilitate the collection and analysis of this unstructured data.
- Sensor Technology: Sensors and IoT devices collect data from physical environments, providing real-time information on variables such as temperature, humidity, and movement. This data can be used in various fields, including environmental monitoring, healthcare, and manufacturing.
- Cloud-Based Data Storage: Cloud computing offers scalable and secure data storage solutions, enabling researchers to store and access large datasets from anywhere with an internet connection. Cloud-based platforms also facilitate collaboration and data sharing among researchers.
- Machine Learning and AI: Machine learning and artificial intelligence (AI) technologies enhance data collection by automating processes, improving data accuracy, and identifying patterns that may not be apparent to human analysts.
These technological advancements have not only improved the efficiency and accuracy of data collection but have also opened new avenues for research and innovation. As technology continues to evolve, the potential for data collection and analysis will continue to expand, offering new opportunities for gaining insights and driving progress.
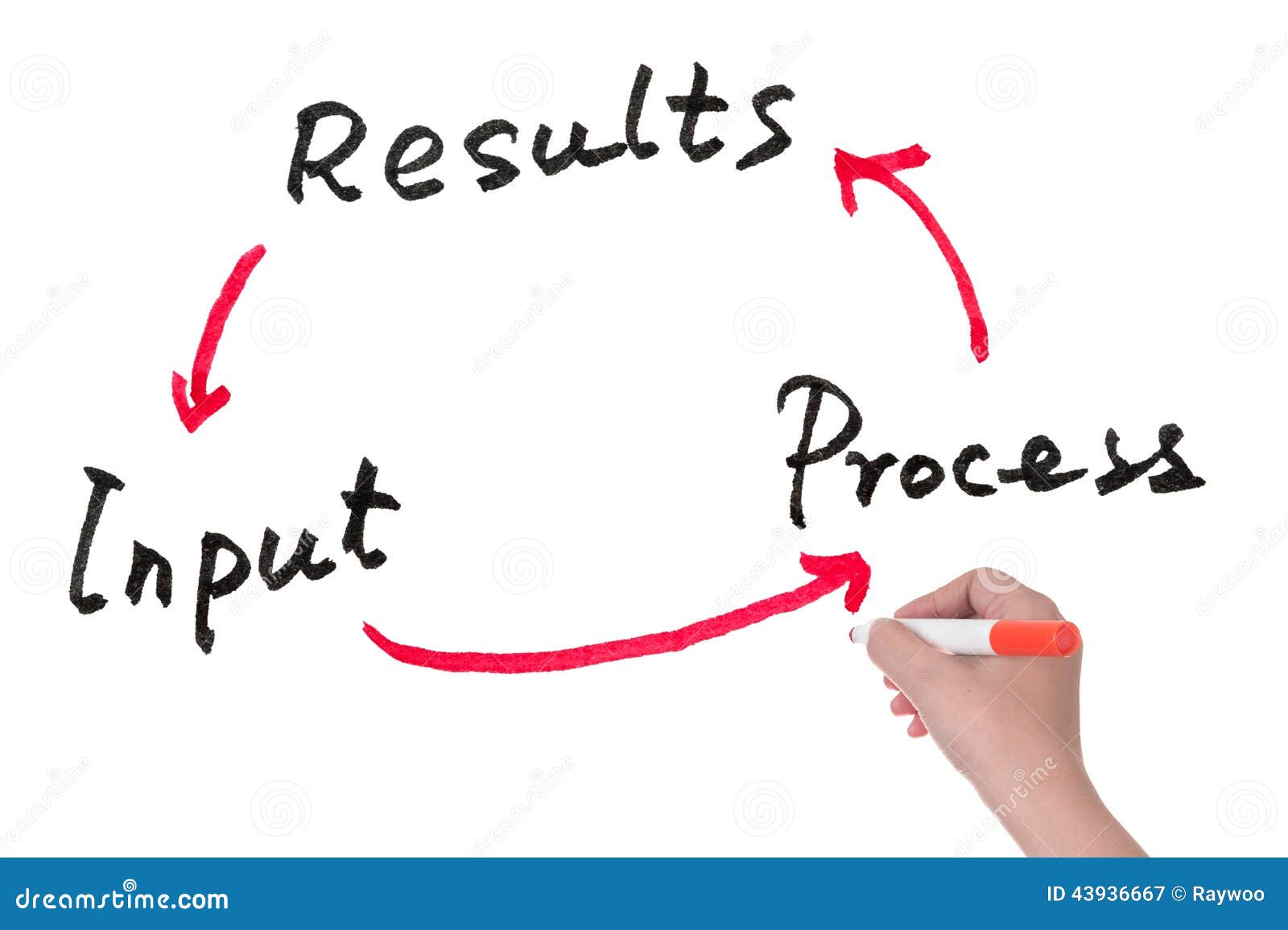
Understanding Data Processing
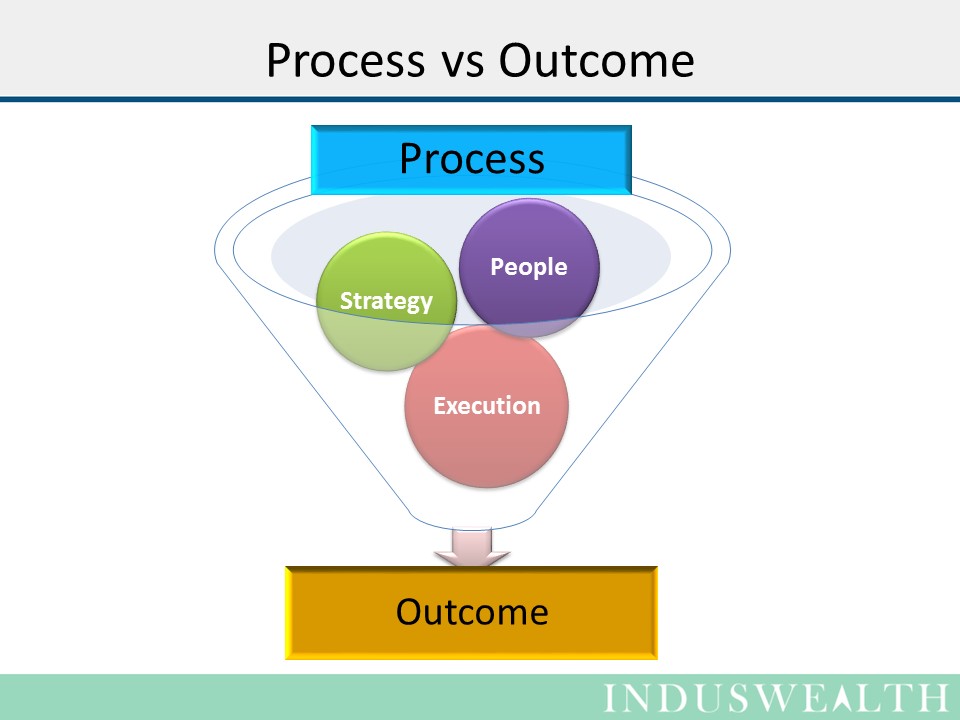
Data processing is the series of operations performed on collected data to transform it into meaningful information. It is a critical step in the research process, enabling researchers to derive insights and make informed decisions based on the data collected. Data processing involves several stages, each contributing to the overall quality and reliability of the results:
- Data Cleaning: The first stage of data processing involves cleaning the data to remove errors, inconsistencies, and duplicates. Data cleaning ensures that the data is accurate, complete, and ready for analysis.
- Data Transformation: Data transformation involves converting raw data into a format suitable for analysis. This may include normalizing data, aggregating variables, or coding qualitative responses for statistical analysis.
- Data Integration: Data integration involves combining data from multiple sources to create a unified dataset. This process ensures that all relevant data is analyzed together, providing a comprehensive view of the research problem.
- Data Analysis: Data analysis involves applying statistical or computational techniques to the processed data to identify patterns, trends, and relationships. This stage is crucial for generating insights and drawing conclusions from the data.
- Data Visualization: Data visualization involves presenting the results of the analysis in a graphical or visual format, making it easier to interpret and communicate findings. Visualizations such as charts, graphs, and dashboards help convey complex information in an accessible way.
The data processing phase is vital for ensuring the accuracy and reliability of the results. By following best practices and employing appropriate methodologies, researchers can derive meaningful insights from the data and make informed decisions that drive progress and innovation.
Steps in Data Processing
Data processing involves several steps that transform raw data into valuable information. Each step plays a crucial role in ensuring the accuracy and reliability of the results. Here are the key steps involved in data processing:
- Data Collection: The first step in data processing is the collection of raw data from various sources. This data serves as the foundation for all subsequent processing and analysis.
- Data Cleaning: Data cleaning involves identifying and correcting errors, inconsistencies, and missing values in the dataset. This step ensures that the data is accurate and ready for analysis.
- Data Transformation: Data transformation involves converting the cleaned data into a format suitable for analysis. This may include normalizing data, aggregating variables, or converting qualitative responses into numerical codes.
- Data Integration: Data integration involves combining data from multiple sources to create a unified dataset. This step ensures that all relevant data is analyzed together, providing a comprehensive view of the research problem.
- Data Analysis: Data analysis involves applying statistical or computational techniques to the processed data to identify patterns, trends, and relationships. This step is crucial for generating insights and drawing conclusions from the data.
- Data Visualization: Data visualization involves presenting the results of the analysis in a graphical or visual format, making it easier to interpret and communicate findings. Visualizations such as charts, graphs, and dashboards help convey complex information in an accessible way.
- Data Interpretation: Data interpretation involves making sense of the results of the analysis and drawing meaningful conclusions. This step involves evaluating the findings in the context of the research objectives and making data-driven decisions.
Each step in the data processing workflow is essential for ensuring the accuracy and reliability of the results. By following best practices and employing appropriate methodologies, researchers can derive meaningful insights from the data and make informed decisions that drive progress and innovation.
Challenges in Data Processing
Data processing can present several challenges that impact the quality and reliability of the results. Addressing these challenges is crucial for ensuring the accuracy and validity of the insights generated. Some common challenges in data processing include:
- Data Quality: Ensuring the quality of the data collected is a significant challenge in data processing. Inaccurate, incomplete, or inconsistent data can lead to erroneous conclusions and undermine the validity of the research.
- Data Volume: The sheer volume of data collected can be overwhelming and difficult to manage. Processing large datasets requires significant computational resources and advanced analytical techniques.
- Data Privacy and Security: Protecting the privacy and security of sensitive data is a critical concern in data processing. Researchers must adhere to ethical guidelines and regulatory requirements to safeguard personal information.
- Data Integration: Integrating data from multiple sources can be challenging due to differences in data formats, structures, and standards. Ensuring that the integrated dataset is accurate and coherent is essential for meaningful analysis.
- Data Interpretation: Interpreting the results of data analysis requires careful consideration of the context and potential biases. Misinterpretation of data can lead to incorrect conclusions and misguided decisions.
- Technical Expertise: Data processing requires technical expertise and familiarity with advanced analytical tools and techniques. Researchers must possess the necessary skills and knowledge to handle complex data processing tasks.
Addressing these challenges requires a combination of technical expertise, best practices, and adherence to ethical guidelines. By overcoming these obstacles, researchers can ensure the accuracy and reliability of the data processing results, leading to more meaningful and impactful insights.
Best Practices for Processing Results
Adhering to best practices in data processing is essential for ensuring the accuracy, reliability, and validity of the results. By following these guidelines, researchers can derive meaningful insights from the data and make informed decisions. Here are some best practices for processing results:
- Ensure Data Quality: Implement data cleaning and validation processes to ensure the accuracy and completeness of the data. This includes identifying and correcting errors, inconsistencies, and missing values before analysis.
- Use Appropriate Analytical Techniques: Select the right statistical or computational techniques for analyzing the data based on the research objectives and data characteristics. This ensures that the analysis is robust and meaningful.
- Maintain Data Privacy and Security: Adhere to ethical guidelines and regulatory requirements to protect the privacy and security of sensitive data. Implement data anonymization and encryption techniques to safeguard personal information.
- Document the Process: Maintain clear and detailed documentation of the data processing workflow, including data sources, methods, and analytical techniques used. This facilitates transparency and reproducibility of the results.
- Validate and Verify Results: Validate the results of the analysis by comparing them with known benchmarks or conducting validation studies. This ensures the reliability and accuracy of the findings.
- Communicate Findings Effectively: Use data visualization techniques to present the results in a clear and accessible format. This helps communicate complex information to stakeholders and supports data-driven decision-making.
By following these best practices, researchers can ensure the integrity and reliability of the data processing results, leading to more robust and impactful insights that drive progress and innovation.
Ethical Considerations in Data Collection and Processing
Ethical considerations play a crucial role in data collection and processing, ensuring that the rights and privacy of individuals are respected throughout the research process. Adhering to ethical guidelines and standards is essential for maintaining the integrity and credibility of research findings. Here are some key ethical considerations in data collection and processing:
- Informed Consent: Obtain informed consent from participants before collecting data, ensuring that they are aware of the purpose, procedures, and potential risks of the research. Participants should have the right to withdraw from the study at any time without penalty.
- Data Privacy and Confidentiality: Protect the privacy and confidentiality of participants by implementing measures such as data anonymization, encryption, and secure data storage. Ensure that personal information is not disclosed without explicit consent.
- Minimize Harm: Ensure that the data collection and processing activities do not cause harm or discomfort to participants. Researchers should prioritize the well-being and safety of individuals involved in the study.
- Transparency and Accountability: Maintain transparency in the data collection and processing procedures, including clear documentation of methods and sources. Researchers should be accountable for their actions and adhere to ethical standards at all times.
- Respect for Cultural and Social Contexts: Consider cultural and social contexts when designing data collection methods and interpreting results. Researchers should respect the diversity and values of the communities involved in the study.
- Compliance with Regulatory Requirements: Adhere to regulatory requirements and guidelines related to data collection and processing, such as the General Data Protection Regulation (GDPR) and other industry-specific standards.
By addressing these ethical considerations, researchers can ensure the integrity and credibility of their research while respecting the rights and privacy of individuals involved in the study. Adhering to ethical standards is essential for building trust and accountability in the research community.
Regulatory Compliance and Data Privacy
Regulatory compliance and data privacy are critical considerations in data collection and processing, ensuring that organizations and researchers adhere to legal and ethical standards when handling sensitive information. Compliance with regulatory requirements is essential for protecting individual privacy and maintaining the integrity of research findings. Here are some key aspects of regulatory compliance and data privacy:
- General Data Protection Regulation (GDPR): The GDPR is a comprehensive data protection regulation that governs the collection, processing, and storage of personal data in the European Union. It establishes strict requirements for obtaining consent, ensuring data security, and providing individuals with rights over their data.
- Data Anonymization: Data anonymization involves removing or obfuscating personal identifiers from datasets to protect individual privacy. This technique ensures that data cannot be traced back to specific individuals, reducing the risk of privacy breaches.
- Data Encryption: Data encryption involves encoding data to protect it from unauthorized access. Encryption is a key component of data security, ensuring that sensitive information is safeguarded during transmission and storage.
- Data Access Controls: Implementing access controls ensures that only authorized individuals have access to sensitive data. This includes using authentication mechanisms, access logs, and role-based permissions to protect data from unauthorized access.
- Data Retention Policies: Data retention policies define how long data is stored and when it should be deleted. These policies ensure that data is not retained longer than necessary and that outdated or irrelevant data is disposed of securely.
- Privacy Impact Assessments: Conducting privacy impact assessments (PIAs) helps organizations identify and mitigate privacy risks associated with data collection and processing activities. PIAs ensure that privacy considerations are integrated into the design of data projects.
By adhering to regulatory requirements and implementing robust data privacy measures, organizations and researchers can protect individual privacy, maintain trust, and ensure compliance with legal and ethical standards. Regulatory compliance and data privacy are essential for preserving the integrity and credibility of research and data-driven initiatives.
Case Studies in Successful Data Collection and Processing
Examining successful case studies in data collection and processing provides valuable insights into best practices and strategies for achieving impactful research outcomes. These case studies highlight the innovative approaches and methodologies used by organizations to overcome challenges and derive meaningful insights from data. Here are some notable case studies in successful data collection and processing:
Case Study 1: Improving Healthcare Outcomes through Data-Driven Insights
A leading healthcare organization implemented a data-driven approach to improve patient outcomes and optimize resource allocation. By collecting and analyzing data from electronic health records (EHRs), patient surveys, and wearable devices, the organization identified key trends and patterns in patient behavior and treatment effectiveness. The insights gained from this data-driven approach enabled the organization to develop personalized treatment plans, reduce hospital readmissions, and enhance overall patient care. The success of this initiative demonstrates the power of data collection and processing in transforming healthcare delivery and improving patient outcomes.
Case Study 2: Enhancing Customer Experience in Retail
A major retail company leveraged data analytics to enhance customer experience and drive sales growth. By collecting data from point-of-sale systems, customer loyalty programs, and social media interactions, the company gained a comprehensive understanding of customer preferences and buying behavior. The analysis of this data enabled the company to personalize marketing campaigns, optimize product assortments, and improve in-store experiences. The successful implementation of data-driven strategies resulted in increased customer engagement, higher sales, and improved customer satisfaction, highlighting the importance of data collection and processing in the retail industry.
Case Study 3: Optimizing Supply Chain Operations
A global manufacturing company used data analytics to optimize its supply chain operations and improve efficiency. By collecting data from sensors, RFID tags, and logistics systems, the company gained real-time visibility into its supply chain processes. The analysis of this data enabled the company to identify bottlenecks, forecast demand, and optimize inventory levels. As a result, the company achieved significant cost savings, reduced lead times, and improved customer satisfaction. This case study illustrates the transformative impact of data collection and processing on supply chain management and operational efficiency.
These case studies demonstrate the diverse applications and benefits of data collection and processing across various industries. By leveraging data-driven insights, organizations can drive innovation, improve decision-making, and achieve their strategic objectives.
Future Trends in Data Collection and Processing
The field of data collection and processing is constantly evolving, driven by technological advancements and the increasing demand for data-driven insights. As we look to the future, several trends are expected to shape the landscape of data collection and processing, offering new opportunities and challenges for researchers and organizations. Here are some key future trends in data collection and processing:
- AI and Machine Learning Integration: The integration of artificial intelligence (AI) and machine learning into data collection and processing will enable more sophisticated analysis and automation of complex tasks. These technologies will enhance the accuracy, speed, and scalability of data processing, unlocking new insights and capabilities.
- Real-Time Data Processing: The demand for real-time data processing is expected to grow as organizations seek to make faster and more informed decisions. Advances in edge computing and streaming analytics will enable real-time data collection and analysis, providing timely insights and improving responsiveness.
- Increased Focus on Data Privacy: As data privacy concerns continue to rise, there will be an increased focus on implementing robust data privacy measures and complying with regulatory requirements. Organizations will prioritize data protection and ethical considerations in their data collection and processing activities.
- Expansion of IoT Data Collection: The proliferation of Internet of Things (IoT) devices will lead to an exponential increase in data collection from connected devices. This will provide new opportunities for data-driven insights in fields such as healthcare, smart cities, and industrial automation.
- Advanced Data Visualization Techniques: Advanced data visualization techniques will play a crucial role in making data insights more accessible and understandable. Interactive dashboards, augmented reality (AR), and virtual reality (VR) visualizations will enhance the way data is presented and interpreted.
- Data Democratization: The democratization of data will empower more individuals and organizations to access and analyze data, leading to greater innovation and collaboration. Self-service analytics platforms and data literacy initiatives will facilitate data-driven decision-making across various sectors.
These future trends in data collection and processing will shape the way organizations and researchers approach data-driven initiatives. By staying ahead of these trends and embracing new technologies, organizations can unlock the full potential of their data and drive meaningful progress and innovation.
FAQs
What is the difference between data collection and data processing?
Data collection is the process of gathering information from various sources for analysis, while data processing involves transforming the collected data into meaningful information through cleaning, transformation, analysis, and visualization.
Why is data quality important in data processing?
Data quality is crucial in data processing because it ensures the accuracy, reliability, and validity of the results. High-quality data leads to actionable insights and informed decision-making, while poor-quality data can result in erroneous conclusions.
How can data privacy be maintained during data collection and processing?
Data privacy can be maintained by implementing measures such as data anonymization, encryption, access controls, and complying with regulatory requirements like GDPR. These measures protect sensitive information and ensure ethical handling of data.
What are some common challenges in data processing?
Common challenges in data processing include ensuring data quality, managing large data volumes, maintaining data privacy and security, integrating data from multiple sources, interpreting results accurately, and possessing the necessary technical expertise.
How do technological advancements impact data collection?
Technological advancements have made data collection more efficient, accurate, and accessible. Innovations such as online surveys, mobile data collection, social media analytics, and sensor technology have expanded the possibilities for data acquisition and analysis.
What are some best practices for ensuring accurate data collection?
Best practices for ensuring accurate data collection include selecting appropriate data collection methods, training data collectors, conducting pilot tests, implementing data validation checks, and documenting data collection procedures.
Conclusion
In conclusion, understanding data collection and processing results is essential for deriving meaningful insights and making informed decisions. By implementing best practices, leveraging technological advancements, and adhering to ethical guidelines, researchers and organizations can ensure the accuracy, reliability, and validity of their data-driven initiatives. As the field of data collection and processing continues to evolve, staying ahead of future trends and embracing new technologies will be key to unlocking the full potential of data and driving progress and innovation.
For further reading and resources on data collection and processing, visit www.data.gov.